Introduction
In this post I talk about three data structures I implemented to compare their performance in different scenarios. The three data structures are Trie, Ternary Search Tree and Radix Tree.
All the code for the data structures as well as the tested scenarios are available in this repo in GitHub.
What is a Prefix Tree?
It is an ordered tree data structure that is used to store a dynamic set of elements where the key is a string. All the data structures that I implemented have the following methods:
| Operation | Description |
|---|---|
| clear | Removes all the content of the data structure |
| find | Returns the value stored in the data structure for a specific key provided |
| insert | Adds a new pair of key and value to the data structure |
| size | Returns the amount of elements stored in the data structure |
| show | Prints the content of the data structure in the dot format |
| erase | Removes the value stored in the data structure for a specific key provided |
| contains | Returns true if there is a value associated to the key provided |
| keys | Returns a std::vectorstd::string with all the keys in the data structure that have the provided prefix. If no prefix is provided, it returns a std::vectorstd::string with all the keys in the data structure. |
| lcp | Returns the longest common prefix of all keys stored in the data structure. |
Trie
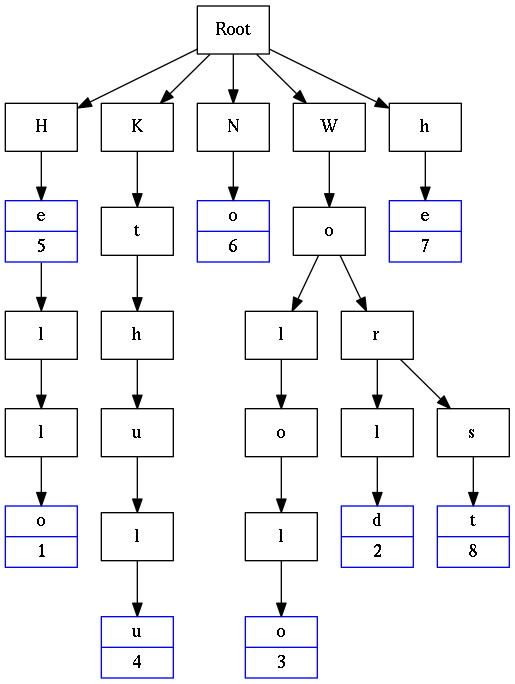
Unlike a binary search tree, none of the nodes in the tree stores the key associated with that node. Instead, its position in the tree defines the key with which it is associated. All the descendants of a node have a common prefix of the string associated with that node, and the root is associated with the empty string. Values are not necessarily associated with every node. Rather, values tend only to be associated with leaves, and with some inner nodes that correspond to keys of interest.
Example of a Trie that contains the keys: “He”, “Hello”, “Kthulu”, “No”, “Wololo”, “World”, “Worst”, “he”:
Ternary Search Tree
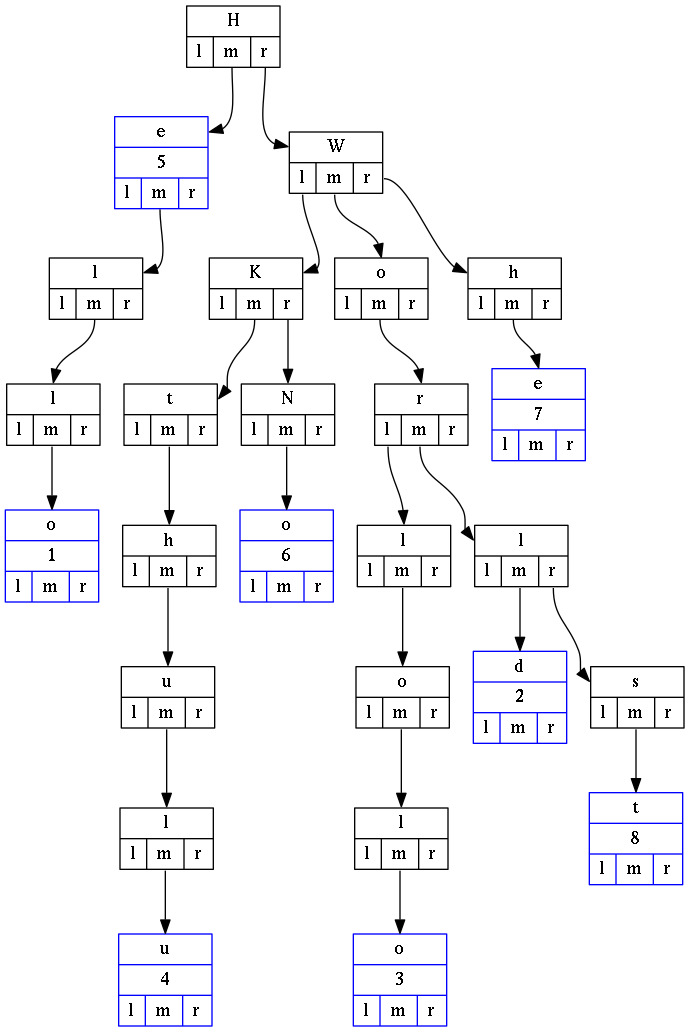
In a Ternary Search Tree nodes are arranged in a manner similar to a binary search tree, but with up to three children rather than the binary tree’s limit of two. Like other prefix trees, a ternary search tree can be used as an associative map structure with the ability for incremental string search. However, ternary search trees are more space efficient compared to standard prefix trees, at the cost of speed.
Example of a Ternary Search Tree that contains the keys: “He”, “Hello”, “Kthulu”, “No”, “Wololo”, “World”, “Worst”, “he”:
Radix Tree
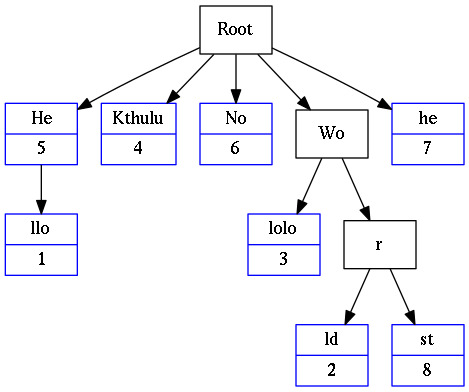
Radix Tree is a space-optimized Trie in which each node that is the only child is merged with its parent. The result is that the number of children of every internal node is at least the radix r of the radix trie, where r is a positive integer and a power x of 2, having x >= 1. Unlike in regular tries, edges can be labeled with sequences of elements as well as single elements. This makes radix trees much more efficient for small sets (especially if the strings are long) and for sets of strings that share long prefixes.
Example of a Radix Tree that contains the keys: “He”, “Hello”, “Kthulu”, “No”, “Wololo”, “World”, “Worst”, “he”:
Comparison
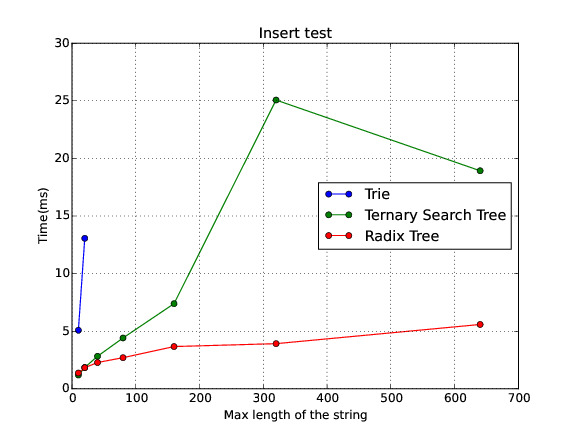
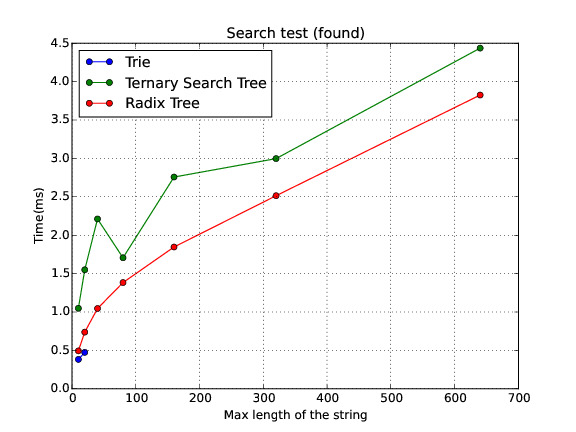
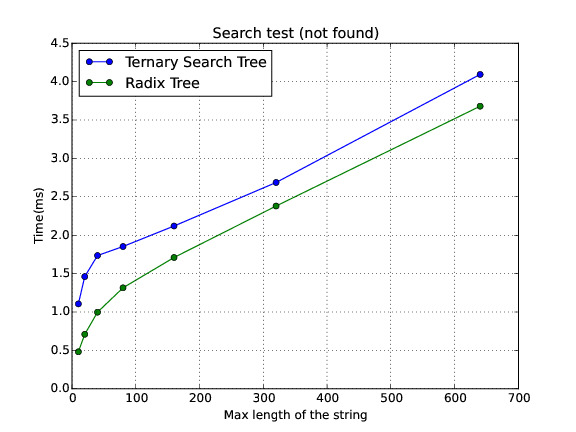
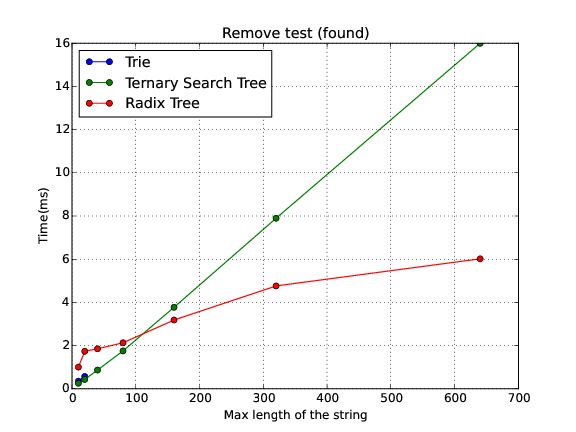
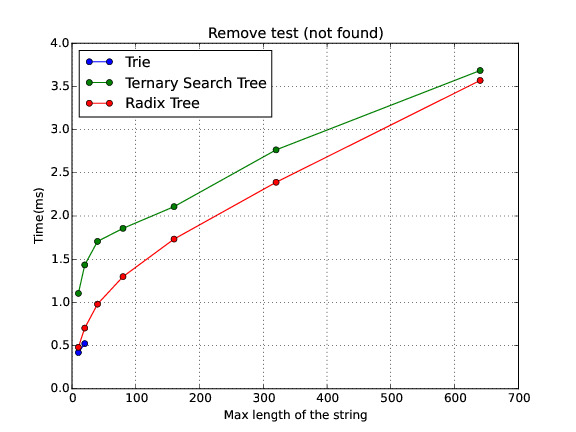
In this section I show a comparison of the performance for the three data structures in different scenarios. Note: sometimes the Trie runs out of memory. Therefore, there is no data on these cases.
Insert
Search
Found
Not found
Erase
Found
Not found
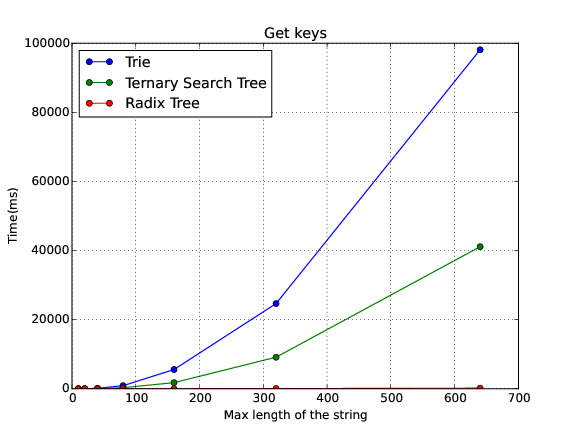
Get keys
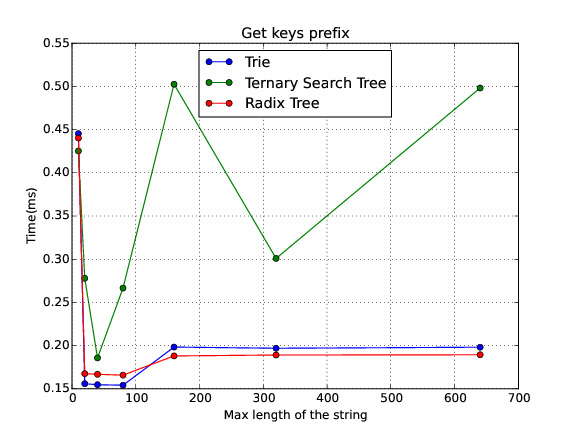
Get keys prefix
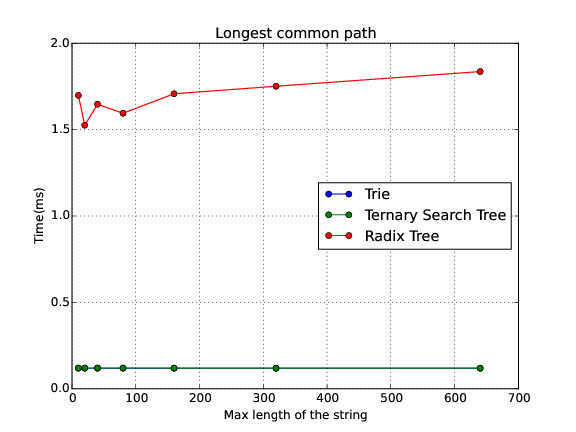
Longest common path
Conclusion
The Radix Tree is in average the best of the three data structures. Nevertheless, I found out a paper where it explains how to implement a Balanced Ternary Search Tree, because one of the weakness of the Ternary Search Tree is that its shape depends of the order of the insertions. I have plenty of work to do regarding this topic but I wanted to share with you some of the preliminar results. Anyway, I am working on writing a paper explaining with more detail this experiment and the way I conducted the expertiment.